An exposition on the propriety of restricted Boltzmann machines

Andee Kaplan, Daniel Nordman, and Stephen Vardeman
Iowa State University
July 31, 2016
JSM - Chicago, IL
http://bit.ly/jsm2016-rbm
Andee Kaplan, Daniel Nordman, and Stephen Vardeman
Iowa State University
July 31, 2016
JSM - Chicago, IL
http://bit.ly/jsm2016-rbm
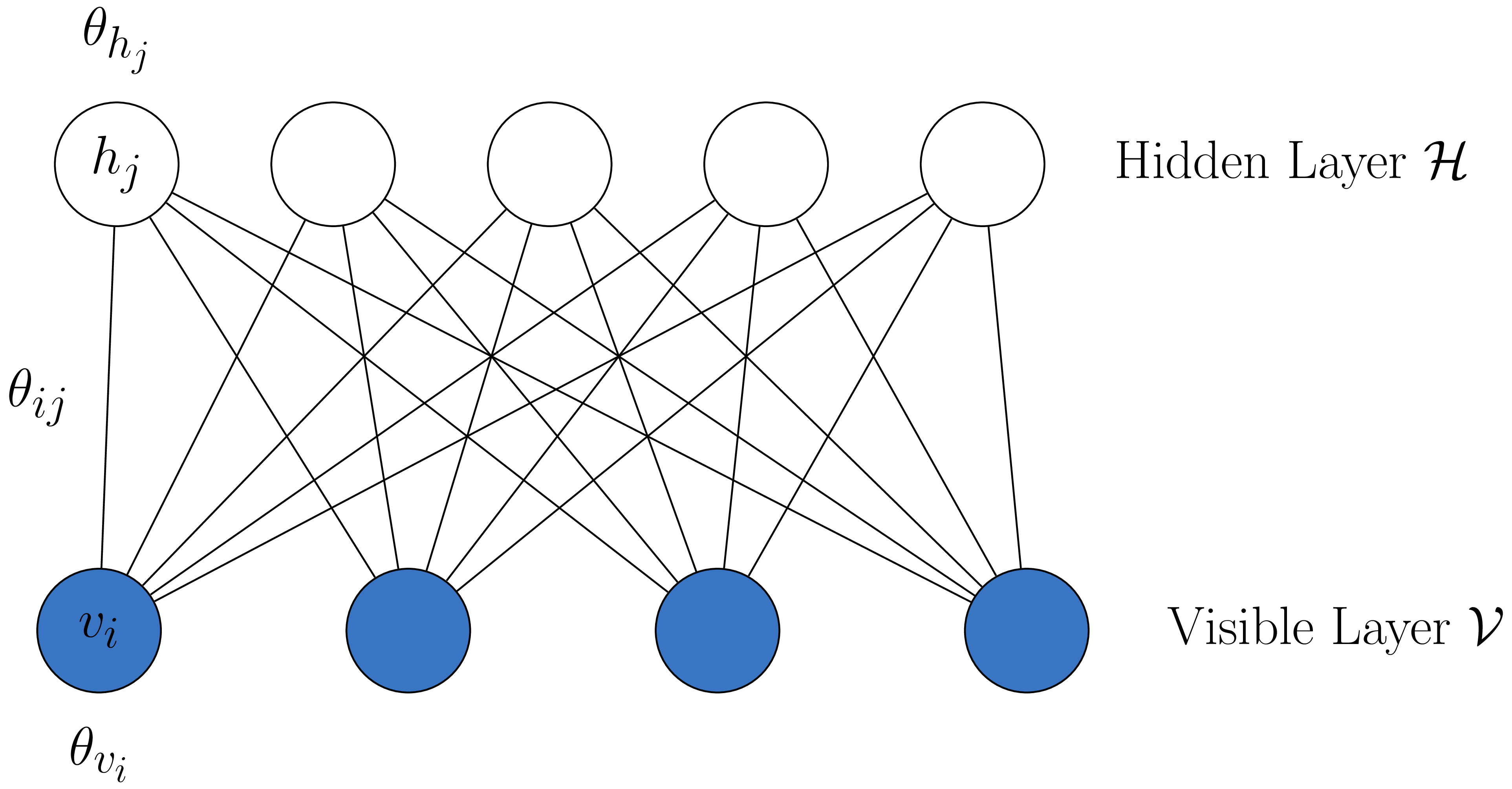
Restricted Boltzmann machine (RBM) with two layers - hidden (\(\mathcal{H}\)) and visible (\(\mathcal{V}\)) (Smolensky 1986).
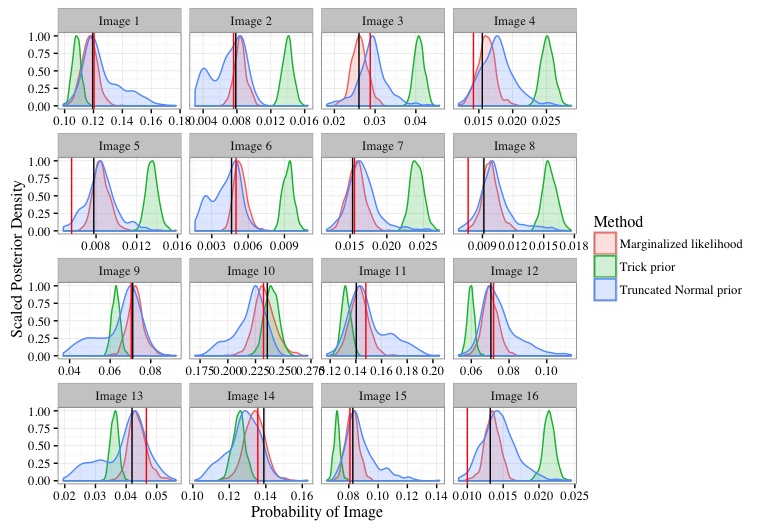
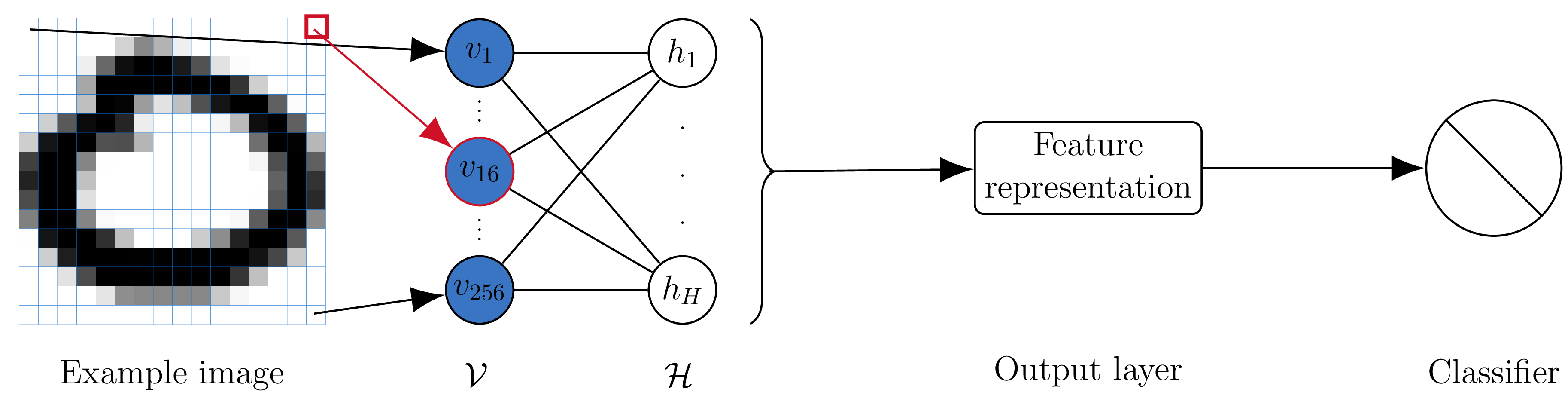 Used for image classification. Each image pixel is a node in the visible layer. The output creates features, passed to supervised learning.
Used for image classification. Each image pixel is a node in the visible layer. The output creates features, passed to supervised learning.
“Deep Boltzmann machine” - multiple single layer restricted Boltzmann machines with the lower stack hidden layer acting as the visible layer for the higher stacked model
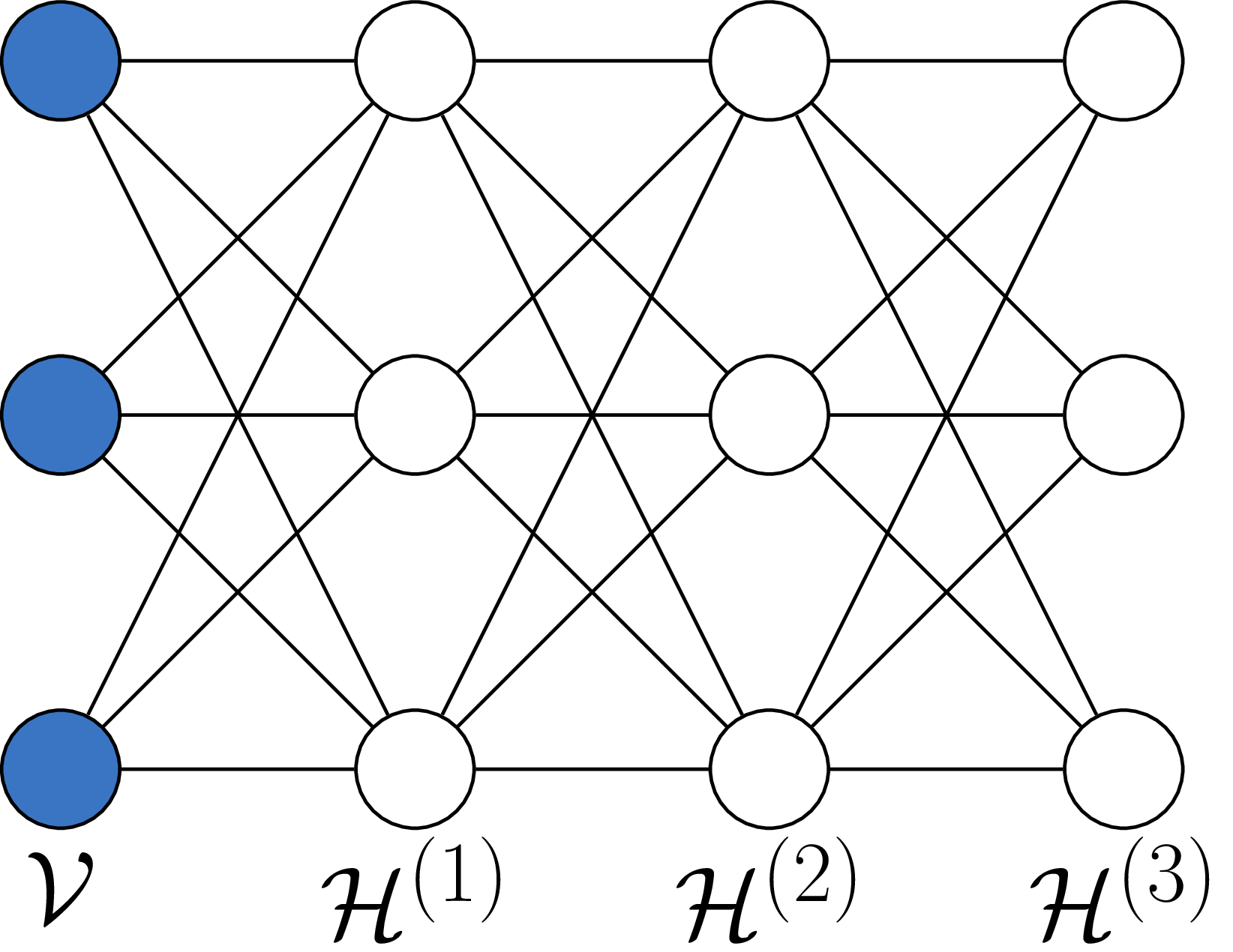
Claimed ability to learn “internal representations that become increasingly complex” (Salakhutdinov and Hinton 2009), used in classification problems.
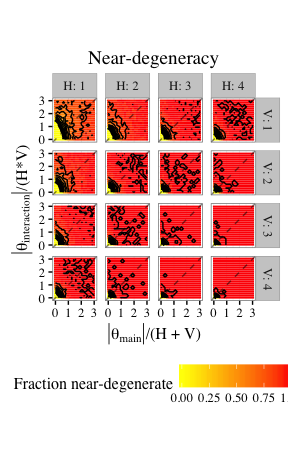
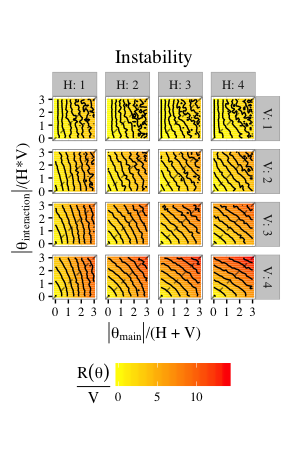
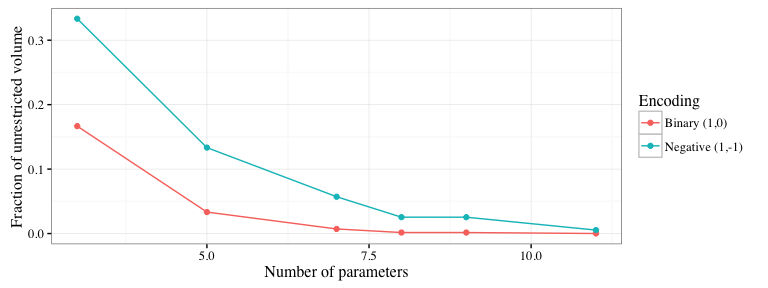
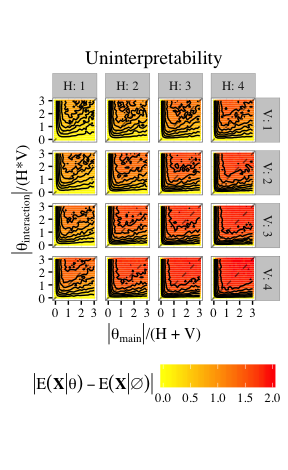 RBMs easily are near-degenerate, unstable, and uninterpretable for large portions of parameter space.
RBMs easily are near-degenerate, unstable, and uninterpretable for large portions of parameter space.

Convex hulls of the statistic space for a toy RBM with \(V = H = 1\) for \(\{0,1\}\) and \(\{-1,1\}\)-encoding enclosed by an unrestricted hull of 3-space.