Reading: What is Data Science?
As part of the course Stat 503 I am taking this semester, I will be posting a series of responses to assigned course readings. Mostly these will be my rambling thoughts as I skim papers.
This week we are reading multiple blog posts (“Data science without statistics is possible, even desirable” and “Some statisticians have a biased view on data science”) by Vincent Granville and chapters 1 and 2 from “An Introduction to Statistical Learning” by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani. These readings are meant to give us muliple perspectives of how data mining, statistical learning, data science fit together.
Definitions
According to James, Witten, Hastie and Tibshirani, “statistical learning refers to a vast set of tools for understanding data.” These set of tools range from simple methods like linear regression to very complex ‘black box’ type tools like Support Vector Machines, as well as unsupervised methods like those used for clustering. The ‘learning’ in statistical learning refers to actually fitting a chosen class (or multiple classes) of models using some sort of training data. The ‘statistical’ in statistical learning indicates thes methods are rooted in statistical theory. Pretty straight forward.
Data mining can mean multiple things to different people (and even to the same person). One agreed upon usage would be the search through data with the goal of finding out interesting pieces or defining “features” from existing datasets - literally “mining” the data for interesting “nuggets”. This is related to statistical learning in that often this is accomplished through use of statistical methods, such as clustering. The term “data mining” actually comes from the database community, which is not surprising since that’s where the big datas call their home.
But what is data science?
Really, what is it? Because I’m not entirely sure. I’m also fairly certain if you ask two people to define the term you will end up with four answers. I can give you my own somewhat vague definition. Data science is the discipline that studies and utilizes data in a systematic and structured way. In no way am I suggesting that this is the only definition of the word, or even the way that the public uses it. This is the definition that I wish would take root though, because I feel it’s a postive and accurate description of a discipline that has made great strides in the last 15 years and could continue to do so if people can collaborate instead of disparaging either the field of data science or the field of statistics in the name of the other.
Can’t we all just get along.
I found Granville’s blog posts to both be very antagonistic. In his posts, he draws a line in the sandbox and says, “this is data science; this is statistics. I don’t want to share my toys.” It seems as though his gripe is with closed-minded statisticians who do not want to consider modern methods as valid. I’m sure that these people are out there, being closed minded. Haters gon’ hate.

However, I don’t necessarily agree with the idea that a huffy blog post meant to split disciplines is the best approach. I would think that the field of data science can only benefit from more good people (even statisticians) being involved. To be fair, I have not read many of the posts that preceded his, which could have put his hackles up. He claims that data science does not need to use what he terms “old statistics” and rather can exist solely in the plane of “new statistics”, which according to him most statisticians do not consider statistics. Phew.
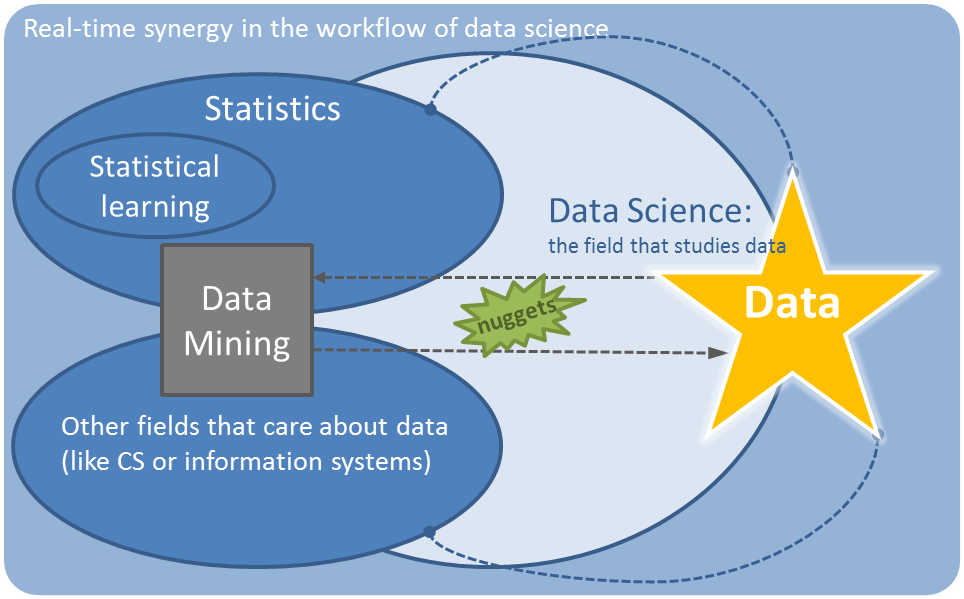
Real-time synergy in the workflow of data science
Aside from being four of my favorite buzzwords, we can achieve “real-time synergy in the workflow of data science” in my opinion by collaborating, using all tools available (and appropriate), and most importantly focusing on data. My ideal view of how statistical learning, data mining, and data science can exist together in harmony is this.
Namaste, data lovers.
blog comments powered by Disqus